Recommendation 4: Ensure future filing reliability
While our study revealed ways that the FECFile interface and software could be enhanced, filers and vendors articulated few concerns with the overall e-filing infrastructure’s reliability. This is praiseworthy: the FEC has, through evolving practice, timely fixes and sustained attention, kept the system working under substantially increased load. In coming years, the FEC will need to support increasing volumes of data while maintaining performance and reliability. To do this, the FEC needs to expand existing work to streamline data flow and build for scalability in the long-term.
This recommendation is part of the 2016 E-Filing study.
Recommendation 1 | Recommendation 2 | Recommendation 3
Technical roadmap and software development process | Research methods
Moving to cloud infrastructure
Invest in cloud infrastructure that can scale to meet demand
Cloud infrastructure refers to hardware that is not owned or maintained by the FEC and can add or subtract resources with minimal effort. While it does require a concerted effort to retool systems and processes for the cloud, the benefits outweigh the costs.
First, the FEC has a real need for scalable infrastructure. The FEC’s traffic, and e-filing in particular is bursty but predictable. The flow of data is driven by filing deadlines that are known in advance. A sizable number of filers wait to get as close to the midnight deadline as possible. (See graph) So, instead of buying and continuously maintaining software at the peak capacity, the FEC can scale down its infrastructure and pay less the majority of the time when traffic and processing requirements are low.
Perhaps more important than cost savings, cloud infrastructure would give the FEC the flexibility to scale up computation and memory capabilities during crunch time. The ability to scale infrastructure as needed is especially helpful if the growth of data outpaces the projected workflow. In the case of e-filing, even the most accurate projections of future load can be made instantly irrelevant by legal rules outside of the FEC’s purview. Legislation and court cases can change or redefine the filing process at anytime in a way that can never be predicted in a five year plan that determines the number of servers to buy.
In Figure 10 below, you can see the growth in receipts, disbursements, and independent expenditures since the seventies. These transactions are the most numerous records by transaction type. There were over 30 million records produced in 2016.
Figure 10 shows how the growth in transactions causes even larger growth in the cumulative amount of data that needs to be cared for. There are about 175 million of these records now, and the data is growing exponentially. These records are being kept, totaled, and analyzed in multiple places. In terms of storage, the EFO office estimates that it has about 7 TB worth of PDF and image files and a database of about 350 GB.
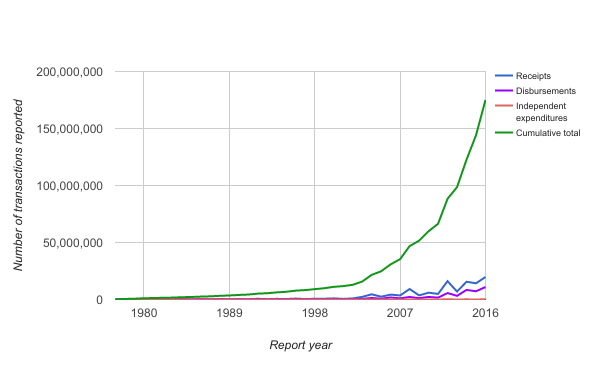
Figure 10. Annual transaction volume (1977-2016) [full size image].
{kind=link}
Another striking attribute of the traffic is that it comes with tremendous peaks and valleys, which you can see below in the figure showing E-filing records per day (Figure 11). Traffic peaks on filing deadlines and the rest of the time it is low. When you buy and maintain your own hardware, you have to purchase the computational and storage capacity for peak times, even though you don’t need all of the capacity most of the time.
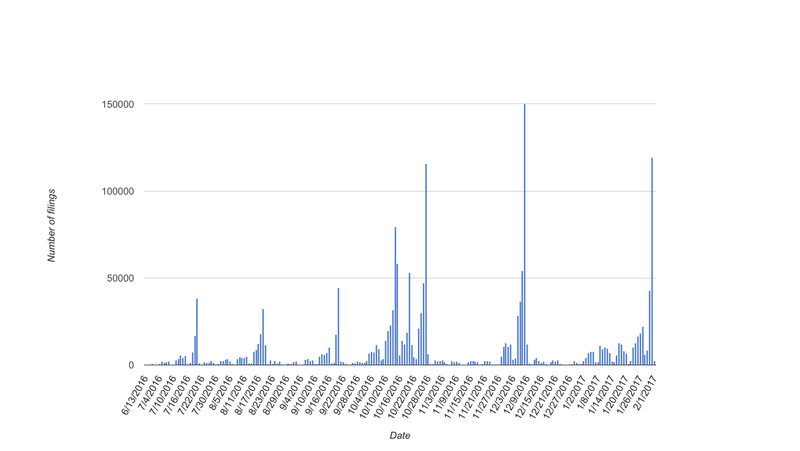
Figure 11. Daily filing volume (6/13/2016-2/1/2017) [full size image]
{kind=link}
In Figure 12 below you can see when e-filing summary reports are processed. They create a normal distribution of records for most of the day, peaking at 3:00pm before a spike in traffic around midnight.
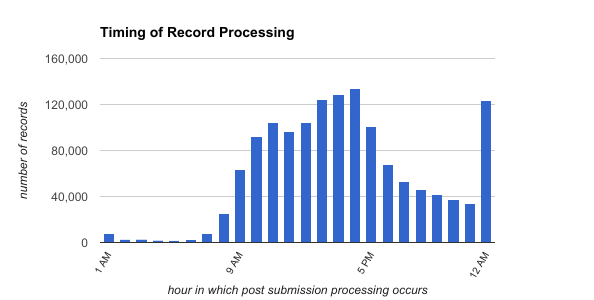
Figure 12. Number of records processed by the hour [full size image].
{kind=link}
As inputs grow, increasing on-demand and parallel processing can maintain or improve the timeliness of making valuable data available to the public.
Moving to the cloud is also a way to unify existing infrastructure. Currently, data is siloed in different databases that cannot easily access each other's information. Figure 13, below, shows the current flow of data from the filers through the servers and databases where it is maintained. While this structure makes sense for private data such as payroll, it makes less sense for less sensitive information.
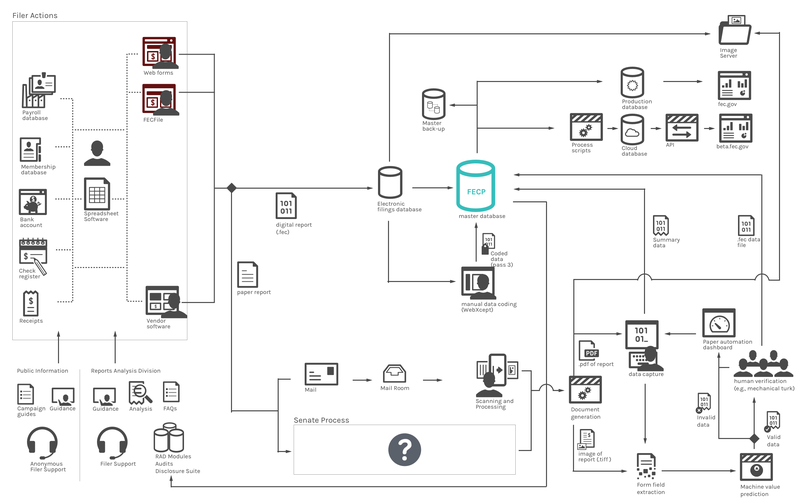
Figure 13. Current flow of data from filers through the FEC to the databases where it is maintained. [full size image]
{kind=link}
Another advantage to moving to the cloud is that the cloud model outsources server maintenance issues like operating system patches. Having those critical updates applied automatically to your infrastructure makes the system easier to maintain. When a security or performance patch to the underlying operating system is needed, the platform as a service is responsible for updating that. In the case of cloud.gov there have been several instances where the underlying system has been patched and the project’s applications are all auto-deployed without effort from the development team. Tracking down servers and projects to patch was a pain point identified in the upcoming cloud study.
Cloud infrastructure also provides cheaper storage for static assets. Amazon's current price structure 7TB would be $161 a month plus up to $0.005 per 1,000 requests. For backups, 7TB could be held in infrequent storage for $88 a month and Glacier, Amazon’s service for long-term backups, for $28 a month plus requests. See the link for exact details and pricing changes.
Another advantage to posting the static assets to Amazon Simple Storage Service (S3) is that S3 uses https so that all the assets would be served over secure connections. This would automatically make a large step toward the OMB’s HTTPS-Only Standard directive, which the FEC is not compelled to follow, but aims to enact to improve the security of its online visitors.
Further, the FEC’s could leverage existing cloud infrastructure that supports Beta FEC to expand e-filing infrastructure. The FEC’s API and the new FEC website are built in the cloud. These webapps leverage Amazon Web Services and Cloud.gov’s platform as a service (PaSS).
General cloud migration issues and logistics will be discussed further in the upcoming 18F cloud study.
Change underlying form design and processes to increase data quality
Like many regulatory agencies, the FEC’s data collection has it’s roots in the paper forms that have traditionally transmitted that data. While paper forms can be helpful models for understanding the data, only thinking of the data as it appears on a paper form can hide the data structures that the forms create. That structure can impact the data intake, presentation and how easy or hard the data is to use. As the volume of data grows, data users can’t read all the paper filings and are more reliant on searching, filtering and linking data to find answers.
Shifting towards a data-centric model can take many iterations, but will ultimately enable a much more flexible and sustainable system. In a data-centric model, forms aren’t the end product, they are simply tools for collecting specific data. While there may always be a paper representation of the data, the guiding principal when crafting what is primarily an electronic data collection system should be to focus on the best way to automatically collect and maintain the data rather than on the manual human approach that the paper forms represent. This concept also came up in the 2013 e-filing study, recommending a transaction focused, rather than form focused approach, and the FEC already has a working foundation for this approach in the current paper processing system.
A. Improve the process by which form changes are designed and implemented
We recommend that any form changes be based on evidence that the change will have a positive impact on filer experience and data quality. Evaluation by real users can deliver evidence of a change’s impact on filer comprehension and data accuracy, among other things, before the change is implemented. A form change is not only an opportunity for a new look on a piece of paper—it is also a chance to better ask for the needed information. Usability testing can also help the forms committee make more informed decisions about information architecture and wording. For example, if there were a few legally correct options for instructions on how to fill in a line item, testing with filers could help uncover which labels were more likely to solicit the correct response.
The FEC faces challenges to changing forms because it doesn’t always have control or warning over when new legislation or judicial decisions require collecting new or different data.
Some of these changes are easy to implement, while others need regulatory changes or legislation to be enacted.
- Candidate ID for independent expenditures One of the most consistent requests from data journalists was to add candidate IDs for independent expenditures. This would allow for FEC data users to attribute expenditures to the candidate that the group is supporting or opposing. Currently, the same name can be represented multiple ways: nicknames are common, various honoria may prefix the name, or a suffix can be attached. On top of that, human error makes it is easy to misspell names. Concurrent members of Congress can even have the same name, such as Rep. Mike Rogers (MI) and Rep. Mike Rogers (AL). These inconsistencies makes the name hard to use in an automated way. Having an ID is a way to programmatically identify candidates in a reliable way and allow for timely data aggregation and reporting. This could be implemented through a candidate lookup field that is populated from the FEC’s API, with consistently spelled candidate names that can provide the ID automatically, taking that burden off of the filer in input and off of data users in analysis.
- Candidate ID when applicable on leadership PAC form Leadership PACs are not legally bound to the candidate, but are often used as a tool leveraged by candidates to gain influence with other members and gain important committee positions. Because of their importance, Beta FEC website usability testing showed many users wanted leadership PACs information linked to the candidate. The way to add and link that information in a structured way is to add the leadership sponsor's candidate ID, when applicable. This change could be added to the Statement of Organization on the Form 1, or the IDs could be added retroactively in the coding process: from 2012 to 2016, there were fewer than 700 of these PACs created, and not all of them have candidates to code.
- A place for a Vice President’s name - For presidential candidates, their running mate is an item required to be collected by regulation, yet it does not have a unique form field. This leads to people entering both names into one candidate name field on Form 2. To fix this, the FEC can add a space on the Form 2 for this field, or create a separate post-convention form for this purpose.
B. Amendments
Amendments are currently processed in a way that often results in the re-submission of entire forms. This can make it hard to identify and track which information is being amended.
The current system processes paper amendments through a series of inferences. These can include what type of filing the amendment is, or when the amendment came in. In some cases, there is not a way to properly track amendments. When evaluating the chain of amendment documents, 18% of reports lack information that enables data users to tell if the document has been amended or if it is amending another document. Ninety eight percent (98%) of the documents with unknown amendment status (amendment or new filing), are paper amendments.
Further improvements can be made by scoping e-filing amendments to include only the information that needs to be amended, rather than replacing the data wholesale. In the current system, one or two small corrections on a large report can result in thousands or even a million new records. A report might be amended multiple times, multiplying the number of records to be maintained with each submission. This creates unnecessarily large data sets, which require more processing and maintenance, without adding much new information. The FEC’s 2013 e-filing study estimated allowing users to file amendments that include only the transactions that changed would reduce filing volume by about 70%. Although it would require a regulation change, scoping e-filing amendments only to include the information that needs to be amended, would enable filers to identify the transaction that needs to be changed or deleted, and then pass along only the information to be changed or deleted for processing.
Additionally, and in the short term, adding form IDs to amendments that link them to the document that the amendment is intended to replace would make the amendment chain more clear to data users. This would enable filers and data users to use the data from the amendment and the existing filing to see what the current data looks like as a whole.
C. Child transactions: memo entries and earmarked contributions
Memo entries and earmarking represent two special case transaction types which, under the current reporting system, are sources of confusion for filers and data consumers.
An earmarked contribution is a contribution the contributor gives to a second party with instructions to give the contribution to a clearly identified candidate or candidate committee. Disclosing these types of transactions requires up to four itemized transactions: the original receipt to the earmarking committee, the disbursement from the earmarking committee to the intended recipient, a receipt to the intended recipient, and a receipt memo entry to the intended recipient. The memo aspect disclosing the earmarking committee of the receipt reported by the intended recipient committee can be part of the receipt transaction that discloses information about the contributor. Representing that transaction twice; once as a receipt as it is coming in to the first committee, and once as a receipt coming to the final committee, would be an improvement. The “memo” aspect of the transaction can be part of each transaction. (See an example earmark receipt in this page of a report.) This would require a change to regulation.
There are additional cases where the itemized data that the same transaction is reported twice — once to show that it received the money, and then a separate line to give context to that transaction. The duplicate transaction is marked as a "memo", much as earmarks are. These transactions should also be unified as a single transaction with more contextual data attached. There are also cases, such as a disbursements with credit card payments, where there can be multiple child transactions.
The memo approach also adds additional overhead for people filing the reports.
"I get the data in import. Because they are consistent in their names, I import their disbursements. I spend a bunch of times doing memo entry, no way to import parent child, those are done by hand because there is no way to import child transactions. I was told that was going to be fixed."
Aside from creating overhead for filers, this process creates data that is more difficult for new data users to understand, as half of the transactions needs to be discarded to create an accurate total. Additionally, not all transactions with memos are “memoed items”, and additional text searches and filtering is needed to calculate totals correctly. To see an example of how this is handled on the current website and API, see the code here.
Duplicative records also causes problems for data users because filers can create data that makes sense in their context, but makes the data harder to use. In the duplicative record, filers often write "see above" when dealing with the purpose in these duplicative entries. People using this data run into problems because the order or filtering of a particular query often produces results that don't preserve the original ordering. Data users then have to look up the previous record relative to that record as it would appear in a data entry system or paper representation. It also makes automated analysis harder when the data you are interested might live in a different record.
To make earmarking more clear, the “memo” concept, with its duplicate entries, should be replaced with one transaction per schedule that includes the donor and conduit information. This would be clearer to filers and data users. Additional user research with prototype testing should be conducted to determine how to make earmarks and contextual information more user friendly.
D. One field, one purpose
For some fields in FECFile and on the paper forms that underlie them, a single field with an identical label can be meant for very different data elements. For example, the “name” field (below) represents different things, depending on the context: when the row represents a conduit committee, “name” refers to the committee name, but when the row represents an individual, “name” refers to the contributor’s name.
Figure 14 shows how the fields that serve dual purposes look on the paper form [full size image]
While the data elements meant for the “name” field might seem similar, the meaning is actually quite different when one names an organization and the other names a person. This pattern of field reuse is employed in several places, including committee name and candidate name, committee ID and candidate ID, and the memo field (where the same form field can contain either a specific attribute or free form notes). When data are stored this way, data users cannot find and use information without creating complex rules or filters — those less technically capable may be excluded from using these data.
We recommend that each form field should only capture one, tightly scoped type of information.
Paper filings processing opportunities
In 2016, electronic filing made up 97.8% of all reports filed (by page volume). The remainder of the filings were filed on paper, and while this represent a small percentage of the total, it still represents a tremendous volume and processing burden on the FEC; as of October 30, 2016, it represented over 535,000 pages of transactions for the year. The vast majority of this volume (91% in 2016) originate from campaign committees involving senators. FECA dictates that these filers must file their reports with the Secretary of the Senate, who is then required to remit these filings to the FEC within two working days of receipt [52 U.S.C. §30102 :G2]. The scope of this study did not involve the Senate or its filers; few of the details of the Senate's process are clear, save the parts that intersect with the FEC.
- While the Secretary of the Senate receives the filings as paper, it is likely that the vast majority of these filers are using either FECFile or vendor provided software to complete the filings, and inspection of a sampling of the forms indicates that they were not handwritten.
"All the senate people [are] not out there printing paper and filling it in by hand. There is no reason they couldn't e-file if there was a system in place to support it."
— Stakeholder familiar with the process
- The senate reports arrive at the FEC as scans of paper pdfs, through a secure FTP process.
- From here, the TIFs are converted to PDFs and stored on a webserver and are then “indexed” for basic metadata to associate them with the committees and make them otherwise findable.
- At this point, document images enter the paper automation process, where they are sent to a contractor who “shreds” the document, a process that divides the document into individual fields for machine interpretation through Optical Character Recognition (OCR) or field-level transcription by contract data entry clerks.
- The output of this process is an e-file (.fec) manifestation of the paper filing that is then coded and processed into the master record, as the files produced by the standard e-filing process are.
The current paper automation process described above replaced one that did not make use of OCR, but rather relied on contract data entry clerks who worked on the whole document, rather than by “shredded” fields. This process upgrade has yielded substantial improvements to the speed of processing—the previous process took closer to a month before the transaction level data was publicly retrievable. The new process is much faster, but still creates many data quality issues—OCR and contract data clerks dealing with “shredded” documents seem more likely to misinterpret an individual field than those dealing with an entire filing. That said, the process continues to evolve, and recently, the forms were optimized to allow OCR software to better capture the data on the paper.
While improvements to the paper process continue and the overall percentage of paper filings volume remains minor, problems continue to affect them, including timely availability of publicly accessible data, substantially increased costs borne by the FEC, and the introduction of substantial errors affecting all members of the ecosystem.
Delays in the data’s availability to the public
The paper process is substantially more time-intensive than the electronic filing process, which is nearly instantaneous. Paper files are remitted from the office of the Secretary of Senate, often around five days after receipt (regulations stipulate files should be remitted within two working days to the FEC); from here the scanned pdfs are pushed to the server the morning after they arrive at the FEC, followed by a process of “Indexing” whereby the committee information and summary finances are hand-entered; this can happen as soon as the next morning but must (and does) be made publicly available within two business days of receipt. After this process, the scanned pdf images are placed in the paper automation process, and take an additional five days, or sometimes longer, before the transaction level data is made available to the FEC, at which point the process mirrors that of the electronic filing process.
Increased costs borne by the FEC
On top of the delay in making this information public, the costs to processing paper are substantial. In 2016, direct contracting costs for processing the paper was $711,000, up from $681,000 in 2015 and projected to rise at least 3% per year, totaling $3.7 million over the next five fiscal years (Table 3). This number almost certainly substantially underestimates the costs involved, as it does not account for the additional staff time needed to track down and reprocess errors, index and code paper forms, and otherwise troubleshoot a substantially more complicated process.
Table 3. Projected costs of paper automation contract
| Fiscal Year | Projected cost of paper automation contract |
|---|---|
| Fiscal Year 2016–2017 | $711,580.60 |
| Fiscal Year 2017–2018 | $732,928.02 |
| Fiscal Year 2018–2019 | $754,915.36 |
| Fiscal Year 2019–2020 | $777,563.31 |
| Fiscal Year 2020–2021 | $800,889.67 |
Increased errors affecting all
On top of being considerably more costly, paper filing also is a significant source of errors. The technology behind OCR software’s ability to recognize and encode a printed character is far from perfect, and the and our conversations across the agency have indicated that the current process could still be improved.
“In October [2016], over 1,400 documents were flagged for repair.”
— Stakeholder familiar with the paper process
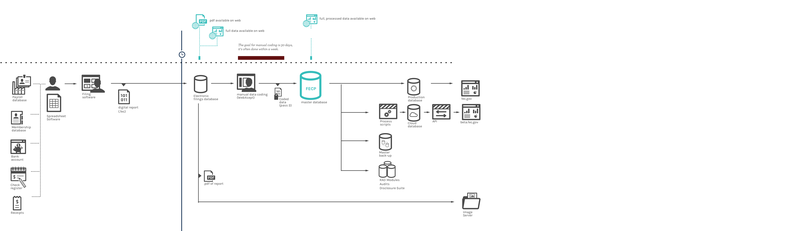
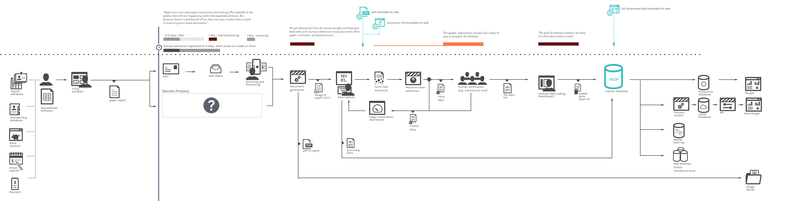
Figures 15 & 16. Comparison of E-Filing (top) [full size image] versus paper process (bottom) [full size image]
{kind=link}
{kind=link}
Potential opportunities
The FEC has previously made recommendations to Congress to amend the legislative requirement, and while we think that should continue, a couple of other opportunities to make headway in the short term have presented themselves.
1. Develop FECFile version 2 as an open source and API driven application
A large portion of the paper filing is from the Senate. FECA states that filings must be made to the Secretary of the Senate, who will forward them to the FEC. Currently, this process is done via paper, but the law doesn't state that it has to be paper, only that it has to be filed with the Secretary of Senate. While the FEC should continue to petition Congress to change the rules such that all campaigns should e-file, it is not in a position to change the way that the Secretary of the Senate chooses to process filings. One possible side-benefit of producing the next version of FECFile as a well documented, open source system for creating data records is that it would make it available for the Senate (and other state and local governments) to implement, substantially lower their costs of standing up an electronic filing system.
2. Make the paper machine friendly
As stated previously, most Senate filers are not filling out the forms on paper by hand. This is especially likely for campaigns producing large numbers of transactions—hand-scribing or typewriting hundreds or thousands of transactions is prohibitively costly and burdensome. The vast majority of filers are using software that either uses the FECPrint module, or uses software that is made by a vendor who is compelled to file according to the FECPrint standard. They then print and submit the report. This is noteworthy: the information originates as digital data and is only converted to a physical paper filing upon submission, only to be converted back into digital data later in the process, at considerable expense, by the FEC.
Translating a digital data artifact to a physical one and back is a situation that numerous other fields have wrestled with. Consider the modern airline industry: today, most passengers book online, where the transaction data begins as digital. On the date of the flight, passengers print their boarding pass, either at home or at an airport kiosk—creating a paper manifestation of their digital transaction. This is then presented to the gate attendant, who scans it in order to confirm the passenger's ability to board the plane. The gate attendant does not attempt to scan the printed characters of the boarding pass to determine the passenger’s eligibility to board—instead the airline encodes and then decodes the data as a bar or QR code, as this has a much greater likelihood of being read properly by the scanning system. If a similar process were employed here, creating machine-friendly paper filings, campaign finance data could be made available much faster, perhaps even approaching the speed of purely electronic filings.
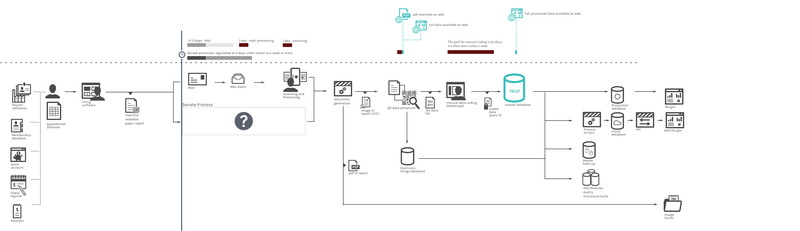
Figure 17. Possible machine readable paper process [full size image]
{kind=link}
Here is a side by side example page of a committee's receipts page on a monthly report (form 3, schedule a), modified to include a QR code that includes the data visible on the page. (Figures 18 & 19)
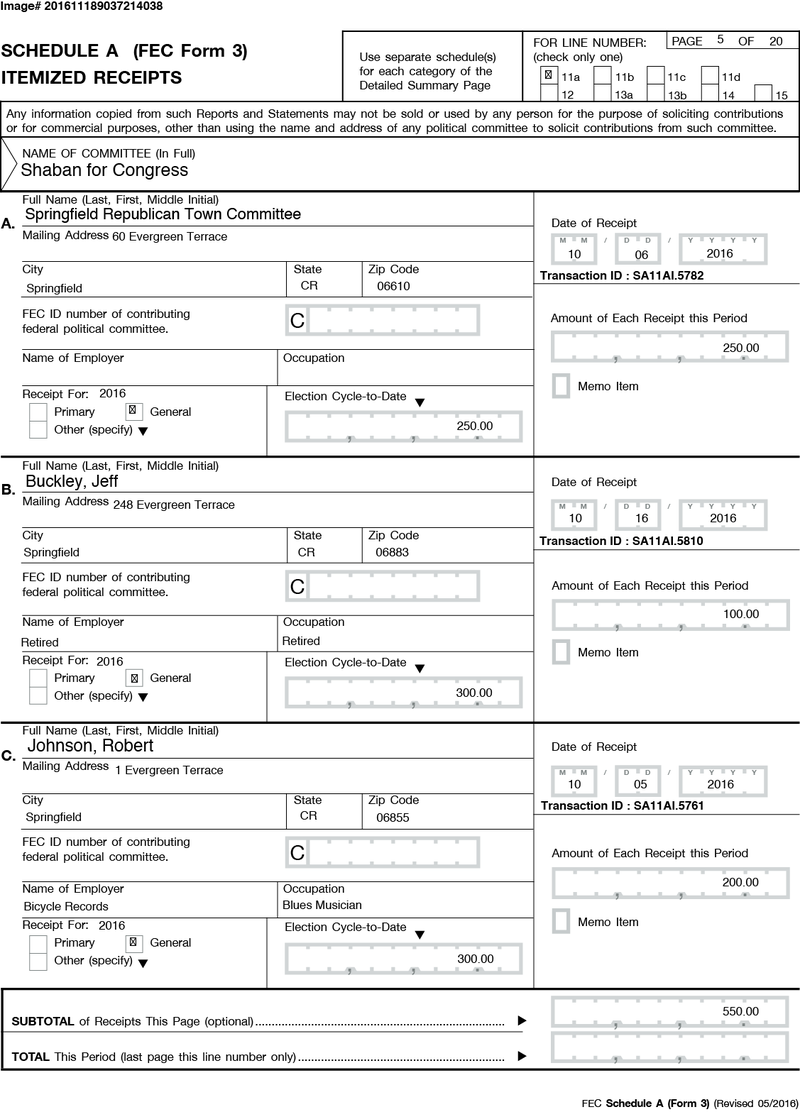
Figure 18. Sample form 3 [full size image]
{kind=link}

Figure 19. Sample form 3, enhanced with a QR code [full size image]
{kind=link}
Improve data formats and structures to manage increased volume
A. Streamline variables as much as possible
The relatively high level of ambiguity in the current filing formats produces data that are difficult for automated processes to handle, which leads to exceptions that must be processed by hand; dissimilar attributes are tracked in the same line item, which makes the data harder to use, and many different forms ask for the same or similar information. Data in each form, both inputs and variable names, should be as consistent as possible.
Form fields and definitions should also be consistent across platforms; paper, FECFile, and published resources should all have the same information about form fields.
As a step toward improving the quality of the data received through e-filing, FEC data experts have already begun looking into how they might address duplicative fields that cannot be standardized by improving metadata within the e-filing system. For example, FEC data experts have analyzed all transactions that can be reported on form 3 and form 3x, marking the differences and similarities as a starting point for reworking the FEC electronic filing formats and standards and specifications. Reworking filing formats, standards, and specifications in this way would also give the FEC greater flexibility with implementing reporting changes caused by court cases or new legislation.
In one instance uncovered by their analysis, FEC data experts identified at least 13 distinct itemized transaction types that are summed together on line 11(a)(i) (itemized individual contributions) which are identified only by specific words and phrases used to describe them rather than any specific unique attributes of the transactions themselves. These include straightforward contributions from individuals but also more complex transactions such as earmarked, in-kind, and partnership contributions as well Indian Tribe contributions and redesignations and attributions of individual contributions. Many other summary lines have similar issues.
Many of the characteristics of these transaction types can be traced back to the days before electronic filing when the standard of being clear on the public record meant understandable to a person looking at a printed page. Today, most reports are being filed as data and the legacy of paper forms has created eccentricities in the electronic filing system which make the data harder to use by developers and analysts. By adjusting the electronic filing formats to produce distinct transactions, these transactions would be machine readable without any special handling. Automated data handling both within FEC data processes and by outside data users could be vastly improved by reducing ambiguity which requires manual categorization to mitigate.
B. Unique, stable identifiers
The FEC data model does not reflect an accurate concept of a person running for office. Each time someone runs for office, they are issued an ID specific to the state and contest in which they are running. Events—such as running for a different office or in a different state—create multiple IDs that can fragment records, and linking those records together again can be challenging. As mentioned before, variation in names (i.e. nick names), as well as multiple people with common names (i.e. Rep. Mike Rogers - MI and Rep. Mike Rogers - AL) makes unifying the records a manual process.
In usability testing for beta.fec.gov, we have consistently seen that people who use the site would like to track data for candidates, even across campaigns. Without person-based IDs for candidates, this is not feasible. Other organizations, such as the Center for Responsive Politics, the National Institute on Money in State Politics and many more use this data to create identifiers for individual candidates and then correlate each candidate’s various IDs. This is a valuable service, but could be better addressed at the root.
Changing candidate IDs also contributes to data errors. Filers might reference an older ID without realizing it changed, or because the information was saved in an auto-fill feature.
The original intent of this ID scheme was to conserve storage when it was more expensive. However, now that the FEC is handling a higher volume of data and more characteristics, there is increased risk of data collisions. (For example, much of the data from the 1970s cannot be used with data after the 1980 cycle because the IDs are not unique and cause records to be mismatched.)
Another instance of this is in filing IDs, which will have dates and information about if things were filed via paper or electronically. This is data that should be represented in the data model directly, rather than inferred by ID. The API and Beta FEC website already try to decode this information and store that the date and time it was processed and how it was processed in its respective data models. Even if the ID scheme does not change, this information, should be stored as data in data fields to make the data modes more straightforward.
Currently, characters of the ID are representing data. A better way to generate unique IDs is to use the UUID standard, this would be beneficial for transactions, files and other IDs that need to be unique. These IDs are long so they are less useful for the kind of IDs people need to transcribe repeatedly like candidate ID.
For candidate and committee IDs, there are some good usability arguments to be made that starting all committee ids with a “C” can help people identify that ID. The current convention is to start a candidate ID with a “P”, “S” or “H” depending on office, this helps identify it as a candidate ID but causes problems if candidates change office. So the letter could stay static even if there is a change in office, or a letter other than “C” could be chosen going forward to lessen confusion. Also, the number of candidates and committees is smaller and made much more infrequently, so an ID with fewer characters than a UUID is easier for people to report.
Going forward, encoding data in relevant data models would help ensure IDs are stable and unique.
C. Expand data “pre-coding” and unify the data architecture
Expand data pre-coding
At points in the process of data intake, the FEC adds metadata not explicitly on the forms to each filing that adds useful context to the data. Generally, these codes are letters or numbers that represent a category: for example, an “S” is added to indicate records that pertain to senate committees, an “I” in the data to represent incumbency. This metadata is either “pre-coded”, that is, added by the software automatically upon submission by the filer, or manually hand-coded by individuals in Reports Processing after the submissions arrive at the FEC.
We recommend that automatic pre-coding be expanded substantially. This will simultaneously reduce the burden on FEC staff to code manually and the time it takes to do so, reduce the potential for human error in coding, and provide additional useful information to campaign finance data users immediately. For example, the e-filing software could leverage the existing API to automatically apply the candidate_id that an independent expenditure was spent for or against. The codes could then be augmented later by Reports Processing staff, as necessary.
Unify the data architecture
We further recommend that the data architecture, including the metadata codes, be standardized, unified, and published for use across the agency. By doing so, these systems can more easily build off of each other's resources, simplify data center architecture, reduce chances of failed data center transport processes, make updates and maintenance easier, and avoid costly work marrying different departments metadata. For example, the project of developing beta.fec.gov’s calendar took weeks longer than estimated because of the difficulties of unifying data across departments—costs that could have been avoided if the codes were aligned across the organization.
Referring to data within the same system makes it even easier to set up triggers. Triggers allow scripts to update data if a condition changes. This is especially important because fillings can be updated, no matter how far back in time they are. For example, if a campaign submits an amendment that changes its spending in the 3rd quarter of 1980, the corresponding totals for that candidate and any other aggregates that are based on those figures will have to change. While amendments that are over five years old make up less than 0.2% of amendments, the FECP master database regenerates all its calculations records nightly to ensure proper handling of these edge cases. We recommend leveraging triggers, partitioning, and materialized views to allow for processes that will only recalculate the totals for that candidate and not every candidate.
Combined, pre-coding, triggers, and unifying the data architecture allows data to be processed continuously instead of batched nightly, which ultimately creates opportunities to have more real time data for the public.
D. Use standard file formats
The FEC has made it easy for data consumers to export and analyse the data it releases by publishing campaign finance data using standard data formats (.csv, .json, and .xml). In the e-filing system, two main file types used: .dcf and .fec. The .dcf files are used to keep local database records for FECFile. The .fec files are ascii delimited text files that filers submit. Neither of these formats are commonly used for data presentation outside of the FEC, and one (the .dcf file type) is used for copyrighted audio.
During our research many groups—specifically, commercial campaign finance software vendors, data journalists, individuals working directly on the FEC system, and filers who wanted direct access to their own data—all articulated a need for more common, open data formats. Much as publishing the submitted data in open, standard formats has made its use easier, the same can be accomplished for the working data. We therefore recommend that the FEC evolve their working files towards more common, open formats.
The future of .dcf and .fec files
While the file type for .dcf files is somewhat dependent on FECFile’s future form, we specifically recommend that .fec files be transitioned to be the more common .csv files. If the next generation of FECFile is a desktop application, it should transition the .dcf files to a local database like sqlite to store the data. Using a local database will speed up data validation checks and improve overall performance and is a common data framework that developers can host, and use to build their own tools. If, on the other hand, FECFile is to be a web utility (as users desire), the data would be stored in a database remotely, either encrypted with the FEC or a with a commercial software vendor. In that case, data exports should be provided for all stored data types as a common format, such as .csv files.